
“Differential privacy” is a powerful, sophisticated, often misunderstood concept and approach to preserving privacy that, unlike most privacy-preserving tech, doesn’t rely on encryption. It’s fraught with complications and subtlety, but it shows great promise as a way to collect and use data while preserving privacy. Differentially private techniques can strip data of their identifying characteristics so that they can’t be used by anyone — hackers, government agencies, and even the company that collects them — to compromise any user’s privacy. That’s important for anyone who cares about protecting the rights of at-risk users, whose privacy is vital for their safety. Ideally, differential privacy will enable companies to collect information, while reducing the risk that it will be accessed and used in a way that harms human rights.
Apple is using this approach in its new operating systems, but last month, an article in Wired exposed ways that the company’s implementation could be irresponsible and potentially insecure. The article is based on the findings of a recent academic paper, which delved deep into the MacOS to discover previously undisclosed details about how Apple built its system. The tech behind Apple’s privacy-preserving data collection is fundamentally sound; as usual, the devil is in the details.
In a three-part series, we’ll describe the way private companies, like Apple, both properly and improperly use differential privacy tools. We’ll explain how companies can adopt differential privacy tools responsibly and how lawmakers can respond appropriately.
In this first post, we’ll look at what differential privacy is and how it works. In the second, we’ll explore the issues that make it complicated, in Apple’s case and beyond, and address some common misunderstandings. Finally, in part three, we’ll look at the ways differential privacy is used in practice and what responsible use might look like.
What is differential privacy?
Differential privacy isn’t, in itself, a technology. It’s a property that describes some systems — a mathematical guarantee that your privacy won’t be violated if your data are used for analysis. A system that is differentially private allows analysis while protecting sensitive data behind a veil of uncertainty.
Differential privacy is a way of asking questions about sensitive data. Let’s say one party, Alice, has access to private information; another, Bob, wants to know something about it. Alice doesn’t want to give Bob access to her customers’ data, so instead they make an arrangement: Bob will asks questions (“queries”) and Alice will give randomized answers that are probably close to the real ones. Bob gets approximations of the answers he wants, but doesn’t learn enough to compromise anyone’s privacy. Everyone wins.
To get technical, differential privacy guarantees that whatever answer Alice might give based on the dataset she has, she would have been almost as likely to give the exact same answer if any one person’s data had been excluded. For anyone thinking about giving their data to Alice, this should be encouraging. Whatever Bob asks, Alice’s answer is likely to be the same whether that person’s data are present or not. It implies that Bob can’t use a query to learn much about anyone’s data no matter what else he knows — even the data of everyone else in the database.
Global vs. local
In general, there are two ways a differentially private system can work: with global privacy and with local privacy. In a globally private system, one trusted party, whom we’ll call the curator — like Alice, above — has access to raw, private data from lots of different people. She does analysis on the raw data and adds noise to answers after the fact. For example, suppose Alice is recast as a hospital administrator. Bob, a researcher, wants to know how many patients have the new Human Stigmatization Virus (HSV), a disease whose symptoms include inexplicable social marginalization. Alice uses her records to count the real number. To apply global privacy, she chooses a number at random (using a probability distribution, like the Laplacian, which both parties know). She adds the random “noise” to the real count, and tells Bob the noisy sum. The number Bob gets is likely to be very close to the real answer. Still, even if Bob knows the HSV status of all but one of the patients in the hospital, it is mathematically impossible for him to learn whether any particular patient is sick from Alice’s answer.
With local privacy, there is no trusted party; each person is responsible for adding noise to their own data before they share it. It’s as though each person is a curator in charge of their own private database. Usually, a locally private system involves an untrusted party (let’s call them the aggregator) who collects data from a big group of people at once. Imagine Bob the researcher has turned his attention to politics. He surveys everyone in his town, asking, “Are you or have you ever been a member of the Communist party?” To protect their privacy, he has each participant flip a coin in secret. If their coin is heads, they tell the truth, if it’s tails, they flip again, and let that coin decide their answer for them (heads = yes, tails = no). On average, half of the participants will tell the truth; the other half will give random answers. Each participant can plausibly deny that their response was truthful, so their privacy is protected. Even so, with enough answers, Bob can accurately estimate the portion of his community who support the dictatorship of the proletariat. This technique, known as “random response,” is an example of local privacy in action.
Globally private systems are generally more accurate: all the analysis happens on “clean” data, and only a small amount of noise needs to be added at the end of the process. However, for global privacy to work, everyone involved has to trust the curator. Local privacy is a more conservative, safer model. Under local privacy, each individual data point is extremely noisy and not very useful on its own. In very large numbers, though, the noise from the data can be filtered out, and aggregators who collect enough locally private data can do useful analysis on trends in the whole dataset. The diagram below shows the difference between local and global privacy. In both cases, raw data stay safely protected within the green box, and untrusted red parties only see noisy, differentially private information.
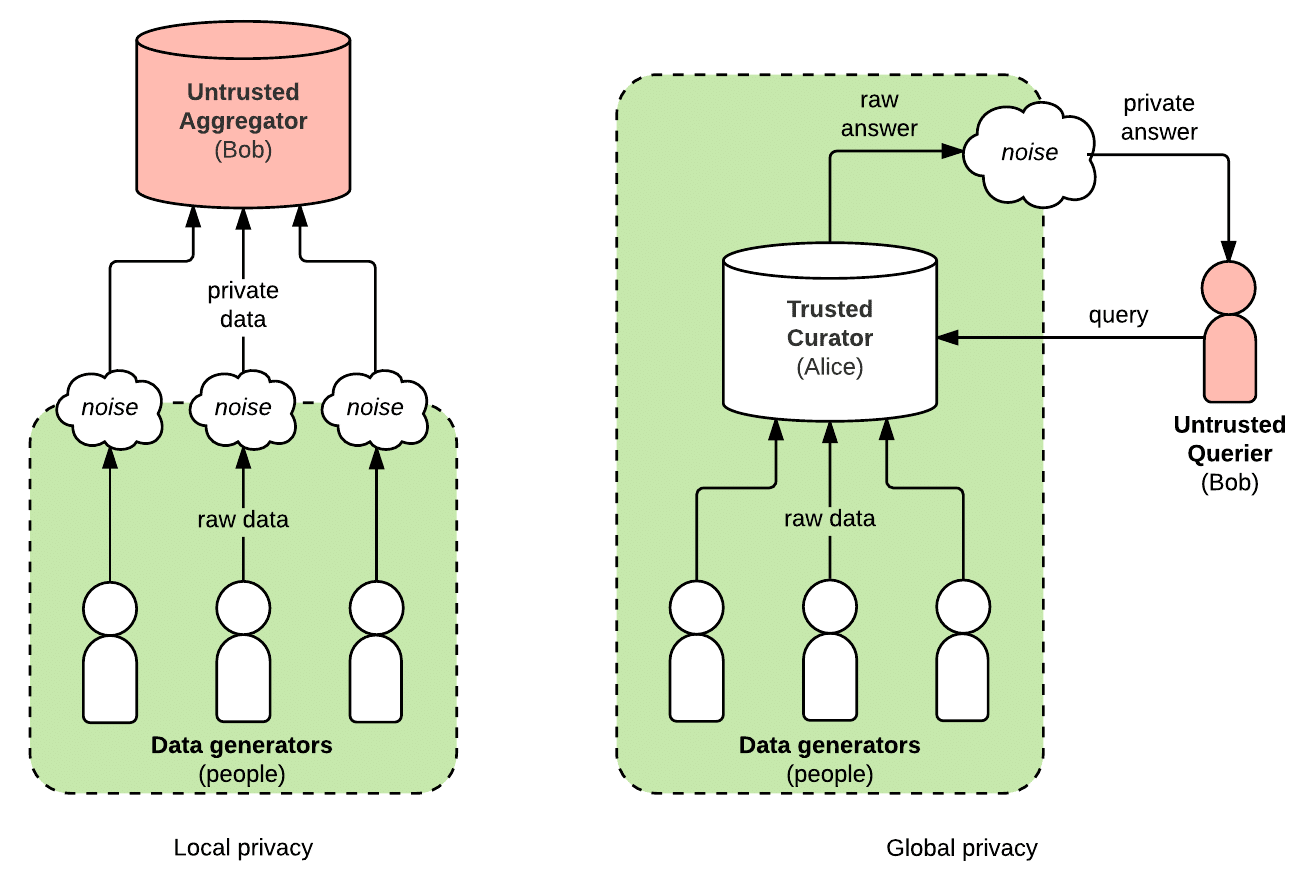
Image credit: Bennett Cyphers
Epsilon (ϵ): the magic number
Differentially private systems are assessed by a single value, represented by the Greek letter epsilon (ϵ). ϵ is a measure of how private, and how noisy, a data release is. Higher values of ϵ indicate more accurate, less private answers; low-ϵ systems give highly random answers that don’t let would-be attackers learn much at all. One of differential privacy’s great successes is that it reduces the essential trade-off in privacy-preserving data analysis — accuracy vs. privacy — to a single number.
Each differentially private query has an associated ϵ that measures its privacy loss. Roughly, this measures how much an adversary can learn about anyone’s data from a single query. Privacy degrades with repeated queries, and epsilons add up. If Bob make the same private query with ϵ = 1 twice and receives two different estimates, it’s as if he’s made a single query with a loss of ϵ = 2. This is because he can average the answers together to get a more accurate, less privacy-preserving estimate. Systems can address this with a privacy “budget:” an absolute limit on the privacy loss that any individual or group is allowed to accrue. Private data curators have to be diligent about tracking who queries them and what they ask.
Unfortunately, there’s not much consensus about what values of ϵ are actually “private enough.” Most experts agree that values between 0 and 1 are very good, values above 10 are not, and values between 1 and 10 are various degrees of “better than nothing.” Furthermore, the parameter ϵ is exponential: by one measure, a system with ϵ = 1 is almost three times more private than ϵ = 2, and over 8,000 times more private than ϵ = 10. Apple was allegedly using privacy budgets as high as ϵ = 14 per day, with unbounded privacy loss over the long term.
These are the fundamentals for how differential privacy works. Stay tuned for our next post, when we’ll dig more deeply into privacy budgets, and talk about a few of the ways differentially private systems can fail to stay private.